Blog
|
6 min read
Why Every AI Strategy Starts With Data
Author
Michał Kowalewski
Last Update
May 18, 2026


An Analytical Framework: Problem → Approach → Architecture → Governance → Business Impact
Now, foundation models are no longer highly competitive, but the data quality and control of an enterprise are. Whether public APIs, several open-weight options, or more, are now easy to access. When teams prioritize models over data contracts, projects slow down after the initial excitement.
For instance, many GCC organizations are experimenting with Retrieval-Augmented Generation (RAG) frameworks. In this scenario, teams integrate a vector database into an LLM but fail to maintain document freshness, chunk quality, missing metadata, or untracked feedback. Results are poor answers, hallucinations, and low reliability.
In the same way, predictive use cases show a similar pattern, such as a churn model trained on incomplete or inconsistent data that may perform well initially but collapse when faced with seasonality, policy updates, or regional regulations, especially across the GCC markets. Hence, the core issue isn’t the algorithm; it’s the missing data contract, its observability, and governance layers.
Now, foundation models are no longer highly competitive, but the data quality and control of an enterprise are. Whether public APIs, several open-weight options, or more, are now easy to access. When teams prioritize models over data contracts, projects slow down after the initial excitement.
For instance, many GCC organizations are experimenting with Retrieval-Augmented Generation (RAG) frameworks. In this scenario, teams integrate a vector database into an LLM but fail to maintain document freshness, chunk quality, missing metadata, or untracked feedback. Results are poor answers, hallucinations, and low reliability.
In the same way, predictive use cases show a similar pattern, such as a churn model trained on incomplete or inconsistent data that may perform well initially but collapse when faced with seasonality, policy updates, or regional regulations, especially across the GCC markets. Hence, the core issue isn’t the algorithm; it’s the missing data contract, its observability, and governance layers.
A data-centric AI strategy treats datasets as living products, not static inputs. It defines Data Service Level Objectives (Data SLOs) such as freshness, accuracy, and coverage, along with building controls to maintain them.
It primarily focuses on THREE engineering pillars that support this approach:
Can you trust the data? Accuracy, freshness, and quality of labels drive performance by determining if models learn from truth or noise. In generative systems (like multilingual LLMs deployed in GCC markets), low-fidelity inputs often cause hallucinations and compliance risk.
Research on Reinforcement Learning from Human Feedback (RLHF) by Ouyang et al. (InstructGPT, 2022) proves that high-quality, targeted preference data can outperform larger, noisier, and raw datasets. (Source: Ouyang et al., InstructGPT)
Pro Tip: Prioritize quality labels over dataset size because a smaller, cleaner dataset can outperform a massive, noisy one.
Does the dataset represent reality? A dataset’s value lies in how completely it represents real-world variance across GCC regions, from Arabic dialects to local regulations. Missing this diversity limits model accuracy. Edge cases, like rare product-channel-region combinations, often decide whether AI succeeds in production.
For the safety-critical UAE and KSA industries, synthetic data can help simulate edge conditions (with caution around privacy and licensing checks). Balanced coverage prevents costly blind spots in regulated sectors like finance, energy, and public services.
Pro Tip: Prioritize quality labels over dataset size because a smaller, cleaner dataset can outperform a massive, noisy one.
Where did the data come from, how was it transformed, and how is it used? Data lineage connects every input to its outcome. It supports reproducibility, compliance, and faster incident response. In faster GCC markets (under ADGM, DIFC, or SAMA), traceability is not optional; it’s mandated. When regulators ask why an AI decision was made, lineage provides the audit trail. Without it, compliance collapses.
As Sibghat Ullah – Head of Machine Learning at CNTXT AI, notes: “These systems succeed when we set data SLOs before model SLOs. Fidelity, coverage, and lineage aren’t academic ideals; they’re the knobs that tune precision, recall, and latency in production.”
A sovereign AI architecture begins with a cataloged, governed data estate, and regionally compliant to UAE- and KSA-based enterprises.
Key components include:
✓ Data catalog with ownership, usage policies, and contracts
✓ Quality services for data freshness and accuracy
✓ Lineage tools tracking transformations and usage
✓ Feature and vector stores inheriting access and contracts
✓ PII (Personally Identifiable Information) detection and masking to safeguard bilingual (Arabic-English) data (image, text, voice) streams under UAE/KSA data residency laws
Feedback loops are critical and engineered from day one. Generative AI systems capture user corrections and ratings; predictive AI logs outcomes and false positives, while predictive systems track performance drift. These feedback signals feed continuous retraining pipelines with auditable trails. This creates a self-improving “data flywheel.”
Evaluation should move beyond benchmarks to domain-specific tests in Arabic and English, ensuring culturally relevant and regulation-safe outputs.
Hala Mansour, Principal Data Architect at CNTXT AI, summarizes: “Treat data like an API with explicit contracts. Producers commit to schema and freshness; consumers commit to usage and lineage. The contract is where governance meets engineering.”
Pro Tip: Prioritize quality labels over dataset size because a smaller, cleaner dataset can outperform a massive, noisy one.
Regulatory bodies like NIST, NCA, DIFC, EU AI Act, ADGM, and SAMA now require documented data governance as the center of mapping AI risk. Compliance is no longer about paperwork; it’s about traceable automated controls.
Operational governance in action with:
✓ Attribute-based access control
✓ Lifecycle-based automated retention and masking
✓ Pseudonymization and tokenization of sensitive data
✓ Model cards and data statements outlining intent and limitations
✓ Lineage capture across data + model registries
Data and model cards should clearly document purpose, bias handling, and retraining frequency. When consent or license terms change, embeddings and cached data must be retraced and deleted, ideally within defined SLA windows.
When data becomes the product, AI metrics align with business metrics. A GCC retail bank modernized its contact center using this data-first AI strategy. Initially, its model-first approach struggled with Arabic dialect variance and compliance audits. By implementing cataloged knowledge bases, retrieval testing, and feedback capture, it boosted first-contact resolution by 9% and cut audit deviations by 30%, all without changing the base model.
Another case: energy companies in KSA improved the mean time between failures using better label fidelity and feedback instrumentation, not by changing models, but by improving data pipelines.
Pro tip: Define data SLOs (freshness, accuracy, coverage) before tuning model hyperparameters, publish both for transparency.
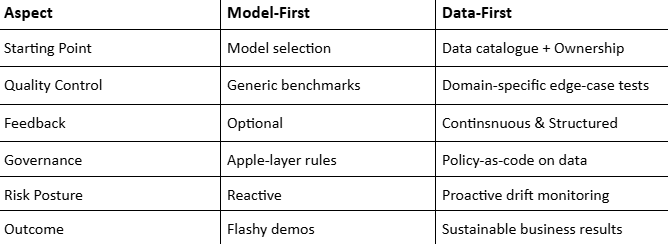
Data localization and linguistic context matter across the UAE, KSA, and GCC enterprises. A sovereign AI stack hosted regionally, featuring bilingual tokenization and Arabic-language evaluation, outperforms importing generic models trained elsewhere.
For public sector AI, lineage systems are crucial. As records move between authorities, purpose and consent must remain intact. A robust lineage system ensures compliance with ADGM and NCA retention laws, minimizing breach risk.
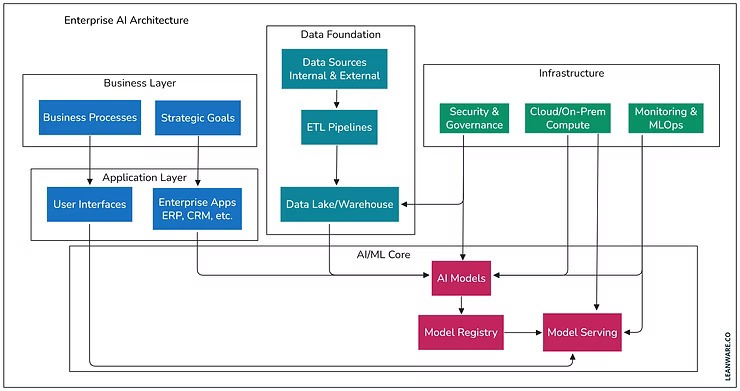
Image Credit: (Leanware)
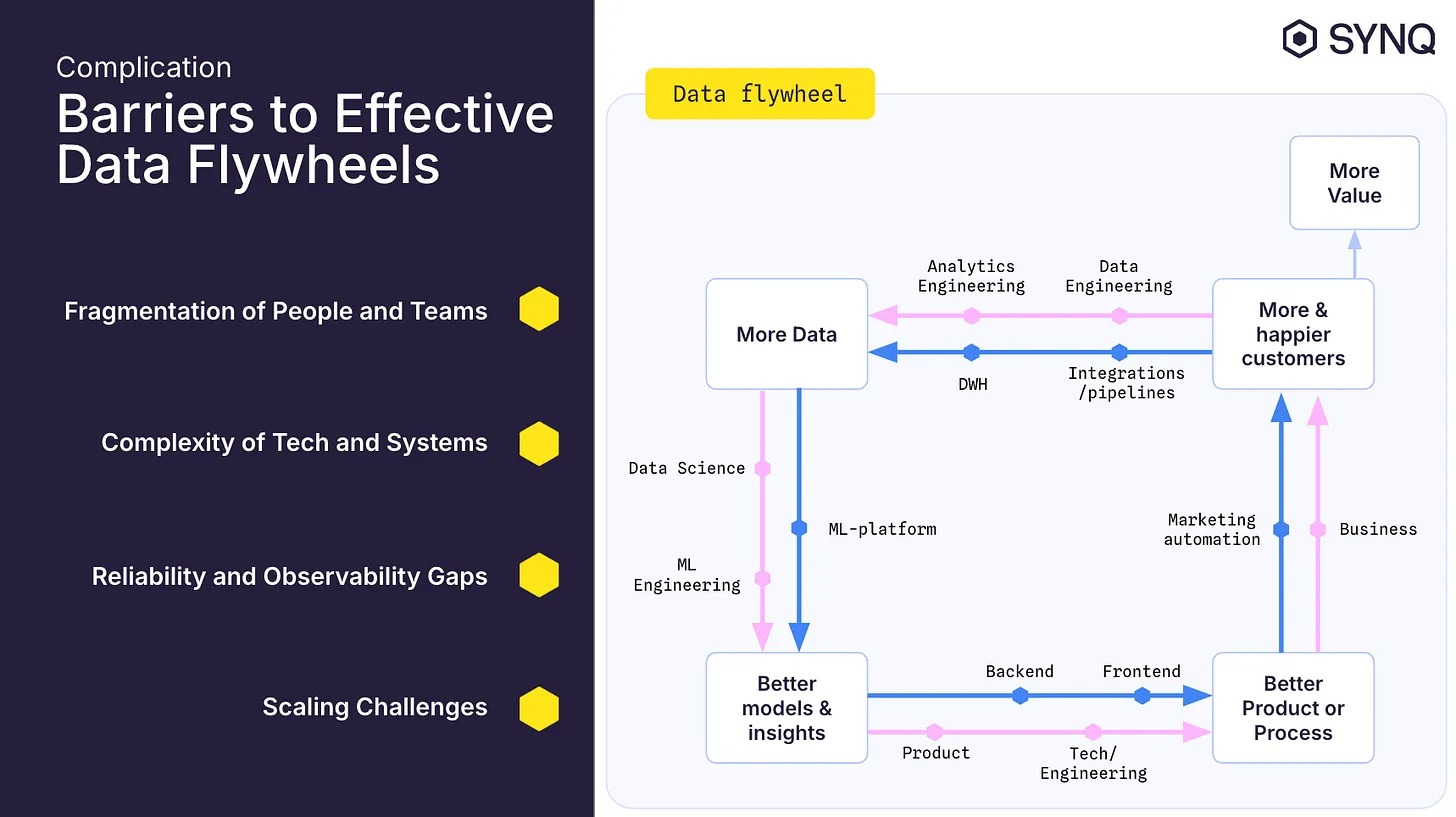
Image Credit: (Robertsahlin)
Caution: Synthetic data can safely enhance coverage but must never replace consent or licensing compliance. Always document generation processes and validate synthetic datasets using privacy leakage tests (like membership inference or attribute inference).
Pro Tip: Prioritize quality labels over dataset size because a smaller, cleaner dataset can outperform a massive, noisy one.
Models will evolve, but the foundation remains the same: trustworthy data. To build reliable AI ecosystems across the GCC, organizations must:
✓ Set measurable data SLOs
✓ Engineer lineage and governance
✓ Expand coverage to reflect regional realities
✓ Tie every data change to a business outcome
For CIOs, CTOs, and regulators in the region, the standard is straightforward. Success isn’t about the sophistication of models; it’s about how responsibly you manage data fidelity, coverage, and lineage to deliver consistent value under governance.

It’s because high-quality, well-governed data is the essential "fuel" for AI models. Data fidelity and lineage ensure compliance, reliability, and consistent business outcomes under regional regulations. Without this foundation, AI initiatives are likely to fail and may waste investment, leading to inaccurate insights with significant risks.
in AI governance, data Service Level Objectives (SLOs) are specific, measurable, internal targets for data quality, like being fresh, accurate, and covering all aspects, along with reliability, availability, and performance of data used by AI systems. This practice guides both predictive and generative AI models.
In order to ensure AI compliance in the UAE or KSA, organizations should implement robust governance frameworks like ISO/IEC 42001. Furthermore, they must execute a sovereign data stack with PII masking, lineage tracing, and residency controls per ADGM and SAMA guidelines. To prepare for regulatory requirements like the UAE’s AI Seal and Saudi Arabia’s SDAIA Self-Assessment is crucial to be involved.
Data lineage connects inputs to outputs, and it’s crucial for quality, audits, transparency, retaining cycles for generative AI systems, and governance of the vast and complex datasets used for training, which directly impact the model’s accuracy, reliability, and compliance with regulations. Further Reading & ReferencesCNTXT AI Resources: